CS6963 Distributed Systems
Lecture 03 Flat Datacenter Storage
Flat Datacenter Storage
Nightingale, Elson, Fan, Hofmann, Howell, Suzue
OSDI 2012
About These Notes
In general, these notes are a mix of extra background to help you get adjusted reading to papers on datacenter systems. It also includes a bunch of questions I've asked myself while reading along. You'll want to be asking yourself the same or similar questions as you go. Sometimes I give answers, other times I've just left questions.
Don't forget to do the Quiz on this paper by the end of the day on Sep 1.
Background
Why are we looking at this paper?
- Lab 2 is primary/backup replication also (though, trivial in comparison).
- Fantastic performance - world record cluster sort.
- Shows off what scale can enable.
- Good systems paper - details from apps all the way to network.
What is FDS?
- A cluster storage system
- Stores giant "blobs" - 128-bit ID, multi-megabyte content
- See "Abstract" below for more info on this.
- Clients and servers connected by network with high bisection bandwidth
- See "Introduction" below for more info on this.
- For big-data processing (like MapReduce)
- Cluster of 1000s of computers processing data in parallel
High-level design - a common pattern
- Lots of clients
- Lots of storage servers ("tractservers")
- Partition the data
- Master ("metadata server") controls partitioning
- Replica groups for reliability
Why is this high-level design useful?
- 1000s of disks of space
- Store giant blobs or many big blobs
- 1000s of servers/disks/arms of parallel throughput
- Can expand over time - reconfiguration
- Large pool of storage servers for instant replacement after failure
- Recreate lost copies from replicas.
Motivating app: MapReduce-style sort
- A mapper reads its split 1/Mth of the input file (a tract, in this paper)
- map emits a (key, record) for each record in split
- map partitions keys among R intermediate files (MxR intermediate files in total)
- sorts each partitioned file
- a reducer reads 1 of R intermediate files produced by each mapper
- reads M intermediate files (of 1/R size)
- produces 1/Rth of the final sorted output file (R blobs)
- FDS sort
- FDS sort does not store the intermediate files in FDS
- a client is both a mapper and reducer
- FDS sort is not locality-aware
- in mapreduce, master schedules workers on machine that are close to the data
- e.g., in same cluster
- later versions of FDS sort uses more fine-grained work assignment
- e.g., mapper doesn't get 1/N of the input file but something smaller
- deals better with stragglers
Abstract
What do they mean by
- locality-oblivious?
- full bisection bandwidth?
- How are these two terms related?
- "blob"
- A big bucket of bytes
- Just think of a big chunk of data that can be accessed with some id.
- Term comes from "binary large object"
How are systems optimized around disk locality today?
- MapReduce: co-locates a map task on each file system server that hosts a block/split of the input file
Single process read/write at 2 GB/s.
- Is this good?
- What would you expect from a hard disk today? ~100 MB/s
- A PCIExpress flash drive? maybe 1 GB/s
Recovers 92 GB of lost disk data in 6.2s
- About 15 GB/s
- How are they going to do that if disks are 100 MB/s and network links at 10 Gbps (1.25 GB/s) in today's datacenters?
Why does recovery speed matter?
What are the tradeoffs to fast recovery? Are there reasons you might want to recover more slowly?
Intro
- Make sure you understand the idea of oversubscription. It's key to the rest
of the paper.
- Switch ports and cabling have both monetary cost and an operational cost in datacenters. Imagine you have to wire 100,000 machines together. How would you do it? You could run one wire and connect them all in a straight line: it'd be cheap and easy to hook up. But, such a topology couldn't transfer much data around. Another option would be a complete graph: every node is linked to every other node - but this would take 10 billion cables and every machine would need 100,000 network cards. Not great.
- Datacenters have to make some tradeoff on this spectrum. In a network that isn't oversubscribed if you take the 'input' link of every node and pair it off randomly another 'output' link of another node such that no two inputs map to the same output, then all of the input to output flows can move data at the full speed that the host is capable of transmitting.
- In today's networks this is usually a 1 Gbps or 10 Gbps NIC attached to a switch sitting at the top of a single rack of machines (a top-of-rack switch).
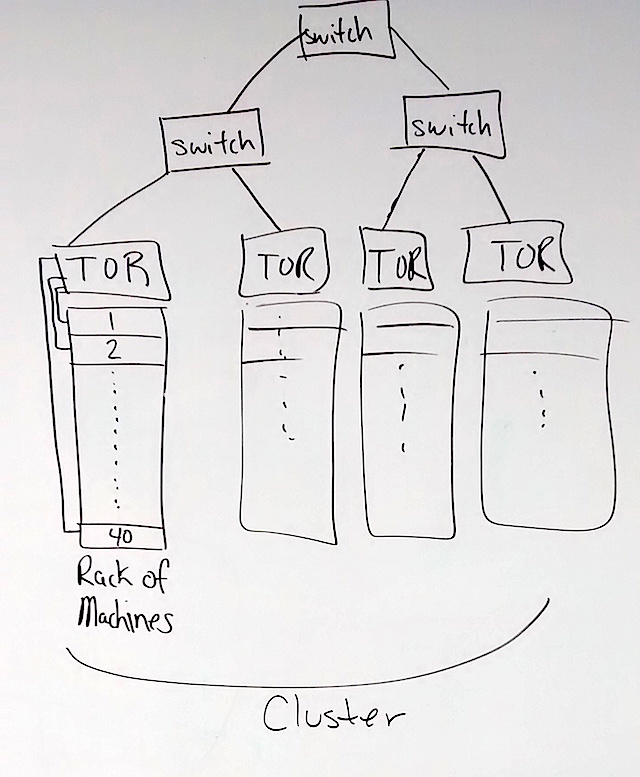
- This figure illustrates.
- Two machines in the first rack together can communicate at full line rate since they are connected via a single switch.
- If a machine wants to talk to a machine in the second rack it must go through a second switch. In an oversubscribed network if we pair the first server in the first rack with the first in the second rack, and so on down the rack and then have all of the machines transmit as fast as they can communication will be bottlenecked on the switch between the two racks.
- It's worth observing that as you go "up" the hierarchy you need enough bandwidth on both "sides" to sustain the full traffic that either side can generate to avoid oversubscription.
- There are toplogies (which are in active use at Google, Facebook, etc) that can avoid oversubscription. See Section 4 for an example.
- In general, datacenter networks do have some levels of oversubscription. It's different at different levels, but it can get severe as one walks up the switch hierarchy. Top-level switches can be oversubscribed by greater than 1000x, meaning that only one in 1000 machines can send data across the top level to the other side at a time (alternatively, all the servers on one side can send to the other side at their link rate / 1000).
- The result of this is that existing datacenters aren't "flat": developers need to think carefully about how to co-locate computation with the data it accesses. This makes life hard...
And hence, the goal of the paper is to erase this complexity by elminating the need for locality.
"Software must also be expressed in a data-parallel style, which is unnatural for many tasks."
- We saw this with the Map Reduce model: not really the way you prefer to program if you don't have to.
For example, our sorting application beat a world record for disk-to-disk sort performance (§6.1) by a factor of 2.8 while using about 1/5 as many disks. It is the first system in the competition’s history to do so without exploiting locality.
- This is 5 x 2.8 = 14 times more efficient than second place.
- And the sort is simpler since it's network/data placement oblivious.
Design Overview
- What should we want to know from the paper?
- API?
- Layout?
- Finding data?
- Add a server?
- Replication?
- Failure handling?
- Failure model?
- Consistent reads/writes? (i.e. does a read see latest write?)
- Config mgr failure handling?
- Good performance?
- Useful for apps?
API
- Figure 1
- 128-bit blob IDs
- Blobs have a length
Only whole-tract (8 MB) reads/writes
Why are 128-bit blob IDs a nice interface?
- Why not file names?
Why do 8 MB tracts make sense?
- (Figure 3...)
What kinds of client applications is the API aimed at?
- and not aimed at?
Write ordering guarantees are similar to what we discussed in class.
- Writer must wait for ack before issuing a second write if they must occur in order.
Why is write atomicity important?
- Do local filesystems provide this?
- Why might it be more important for this system than a local filesystem?
Data Placement
- How do they place blobs on machines?
- Break each blob into 8 MB tracts
- "TLT" maintained by metadata server
- for blob g tract i and TLT size n, slot = (hash(g) + i) mod n
- TLT[slot] contains list of tractservers w/ copy of the tract
- Clients and servers all have copies of the latest TLT table
Example four-entry TLT with a single copy of each tract:
0: S1
1: S2
2: S3
3: S4
suppose hash(27) mod 4 = 2
then the tracts of blob 27 are laid out:
S1: 2 6
S2: 3 7
S3: 0 4 8
S4: 1 5 ...
FDS is "striping" blobs over servers at tract granularity.
Why have tracts at all? why not store each blob on just one server?
- What kinds of apps will benefit from striping?
- What kinds of apps won't?
How fast will a client be able to read a single tract?
Where does the abstract's single-client 2 GB number come from?
- What's the limiting factor for a client reading data from 256 machines?
- Section 4: each machine has a dual port 10 Gbps network card.
Why not hash(g + i)?
- Explained halfway though 2.2.
- Make sure this makes sense.
- Think about throwing n balls into n bins:
- Average number of balls in each bin must be 1.
- Max number of balls in each bin can be high (in fact it grows with n).
- Reading a file is limited by the single server with the most tracts from that file.
- One easy way to guarantee max read bandwidth for a file is to do round-robin of tracts to servers.
- This maximizes perf for a single file, but does it in general? Why or why not?
How many TLT entries should there be?
- How about n = number of tractservers?
- Why do they claim this works badly? Section 2.2.
- Think about 100 clients all writing massive files to the servers.
- Some disks may be (unexpectedly) fast and others (unexpectedly) slow.
- Or perhaps a two of the clients end up talking to the same server at the same time.
- This is like someone tapping their brakes on the highway.
- Eventually, all of the clients get 'piled up' at the slow disk regardless of where they started in the TLT.
- After this the clients all 'attack' the same servers in the same order, interfering with one another and slowing everything.
- Effectively clients bunch up/convoy and cause hotspots and uneven load.
- Using several permutations of the hosts fixes this.
- This creates several random walks across the servers in different orders.
- Could this/does this hurt performance/parallelism?
TLT is rebuilt from tractservers, since they know their position in the TLT.
- What if an old tractserver comes back to life that has the same slot as a newer server?
- Section 3.2 eventually answers this question.
If we expect a server to fail twice a year and we have 256 machines, how often will the TLT need to be modified?
Metadata
Why not the UNIX i-node approach instead of the TLT?
- Store an array per blob, indexed by tract #, yielding tractserver
- So you could make per-tract placement decisions
- e.g. write new tract to most lightly loaded server
- If these were stored at/with tract -1, then metadata would also be randomly scattered.
Why do they need the scrubber application mentioned in 2.3?
- Why don't they delete the tracts when the blob is deleted?
- Can a blob be written after it is deleted?
Why is extend seperate from write? Why doesn't write beyond the end of file extend it?
- Creates headaches for atomicity. The write and the length are on different machines.
Replication and Recovery
Must choose server pairs (or triplets) for TLT entries for replication
What is the problem that the two-phase commit on the metadata solves?
- Does it solve all of the problems?
- What happens if both replicas succeed at "prepare" and then one of them crashes?
- We'll discuss this in more detail when we talk about two-phase commit in class.
Failure Recovery
Why are centralized metadata lookups at the metadata server considered a scalability threat when the metadata server must receive pings from all tractservers?
What happens in the "tractserver dead" steps when one of the tractservers never acks the modified TLT?
Why bother with the "partial failure recovery"?
- Isn't recovery supposedly near-instantaneous anyway?
If a tractserver's net breaks and is then repaired, might it serve old data?
What happens when the metadata server crashes?
- "an operation must ensure the old one is decommissioned and start a new one"
- How easy is it to be sure that a alleged "dead" tractserver isn't still servicing client requests?
- It sounds like in the FDS of this paper, one had to manually intervene when a metadata server failed.
While metadata server is down, can the system proceed?
- Is there a backup metadata server?
How does rebooted metadata server get a copy of the TLT?
Does their scheme seem correct?
- How does the metadata server know it has heard from all tractservers?
- How does it know all tractservers were up to date?
- What if?
- A tractserver crashes
- The metadata server updates the TLT entries for the crashed server
- A client issues writes to the replacement tractserver
- The replacement crashes
- The original tractserver comes back to life
- The metadata server crashes
- The metadata server TLT is recovered using the original tractserver's knowledge
- What can be done to prevent this?
- Can the TLT version numbers help?
- Can they solve the problem completely?
Replicated Data Layout
Would this be a good choice for choosing TLT rows?
0: S1 S2
1: S2 S1
2: S3 S4
3: S4 S3
...
- How long will repair take?
- What are the risks if two servers fail?
Is there a benefit to this approach?
- It turns out there is, but it's subtle; ask me about it in class.
Why is the paper's n^2 scheme better?
- TLT with n^2 entries, with every server pair occurring once
Think about what happens when a tractserver fails; it is necessarily paired with every other disk in the cluster in some row in the TLT.
- This means at least some data can be pulled from every disk in the cluster when a tractserver fails in order to do repair.
- A different random server is going to be popped into each hole in the TLT that the crashed tractserver left.
- The new tractserver can grab replicas from any of the other peers left in that row.
How long will repair take?
What are the risks if two servers fail?
How big will this table be?
- 1,000 disks (not a large cluster)
- 1,000 * 1,000 = 1M, so many megabytes
- 10,000 disks? 100M, so gigabytes
Why do they actually use a minimum replication level of 3?
- Same n^2 table as before, third server is randomly chosen
- What effect on repair time?
- What effect on two servers failing?
- What if three disks fail?
Cluster Growth
Adding a tractserver
- To increase the amount of disk space / parallel throughput
- Metadata server picks some random TLT entries
- Substitutes new server for an existing server in those TLT entries
How do they maintain n^2 plus one arrangement as servers leave, join, and crash? They don't seem to. What does this mean long term?
How long will adding a tractserver take?
What about client writes while tracts are being transferred?
- Receiving tractserver may have copies from client(s) and from old srvr
- How does it know which is newest?
Consistency Guarantees
What if a client reads/writes but has an old tract table?
Replication A writing client sends a copy to each tractserver in the TLT. A reading client asks one tractserver.
Why don't they send writes through a primary?
What problems are they likely to have because of lack of primary?
- Why weren't these problems show-stoppers?
Networking
Here's a visualization of how they've wired things up. I got bored of drawing links, but it should give you a good idea of what it takes to build a full bisection bandwidth network.
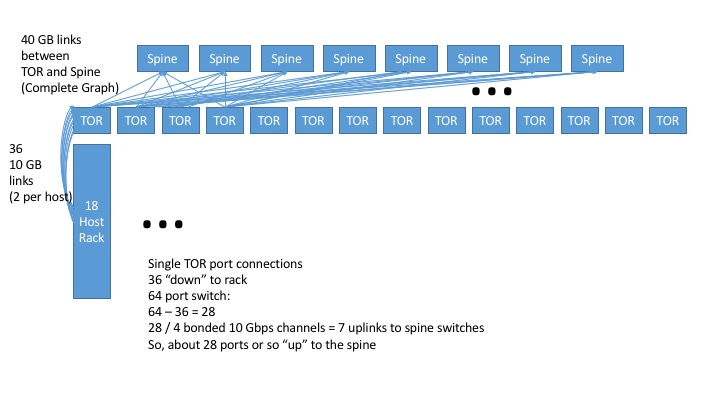
- This approach requires 8 x 14 = 114 cables between the 14 racks.
- Does this seem worth it?
- What if we just cut it back to one spine switch?
- What would it look like then?
- What would be the oversubscription/bisection bandwidth?
- If you had to build this how would you physically arrange the switches and racks?
Microbenchmarks
How do we know we're seeing "good" performance?
- What's the best you can expect?
Figure 4a: why starts low? why goes up? why levels off?
- Why does it level off at that particular performance?
Figure 4b shows random r/w as fast as sequential (Figure 4a).
- Is this what you'd expect?
Why are writes slower than reads with replication in Figure 4c?
Applications
Sort
If you had to choose between using FDS and UCSD TritonSort for massive uniformly-distributed fixed-size-record data which configuration would you use?
- Which one is cheaper to run?
Where does the 92 GB in 6.2 seconds come from?
- Table 1, 4th column
- That's 15 GB / second, both read and written
- 1000 disks, triple replicated, 128 servers?
- What's the limiting resource? disk? cpu? net?
How big is each sort bucket?
- Is the sort of each bucket in-memory?
- 1400 GB total
- 128 compute servers
- Between 12 and 96 GB of RAM each
- Say 50 on average, so total RAM may be 6400 GB
- Thus sort of each bucket is in memory, does not write passes to FDS
- Thus total time is just four transfers of 1400 GB
- client limit: 128 * 2 GB/s = 256 GB / sec
- disk limit: 1000 * 50 MB/s = 50 GB / sec
- Thus bottleneck is likely to be disk throughput
Related Work
- Why might Google have been interested in to smaller "tracts" in GFS down from 64 GB?