|
A thread, as a leaf node of the scheduling hierarchy, can only be scheduled when each scheduler between it and the root of the hierarchy schedules it at the same time. So, a key question is “can a given scheduling hierarchy provide threads with the guarantees that they need in order to meet their deadlines?” Clearly, some arrangements of schedulers are flawed. For example, suppose that a hierarchy includes a real-time scheduler that is scheduled using a time-sharing scheduler. Since the time-sharing scheduler makes no particular guarantees to entities that it schedules, the real-time scheduler cannot predict when it will receive CPU time, and therefore it cannot promise threads that it schedules that they will be able to meet their deadlines.
This chapter develops a system of guarantees about the ongoing allocation of processor time. Guarantees formalize the scheduling properties provided by a large class of multimedia schedulers, and allow these properties to be reasoned about. By matching the guarantee that one scheduler provides with the guarantee that another scheduler requires, and by using conversion rules that allow a guarantee to be rewritten as a different guarantee, complete scheduling hierarchies can be constructed with the assurance that the leaves of the hierarchy will actually receive CPU time according to the distribution they were promised.
Guarantees are the basic abstraction for reasoning about the ongoing allocation of processor cycles to real-time schedulers and threads. A guarantee is a contract between a scheduler and a virtual processor (VP) regarding the distribution of CPU time that the VP will receive for as long as the guarantee remains in force. The meaning of a particular guarantee is defined in two complementary ways:
Both aspects of a guarantee are important: the formal statement is used to reason about scheduler composition, and the correspondence with a scheduler implementation is used to provide a thread with the kind of scheduling service that it requested or was assigned. Establishing a correspondence between the two parts of the definition--proving that a particular scheduler implementation provides some scheduling behavior--is not within the scope of this dissertation.
The distinguishing characteristics of guarantees are that they describe bounds on the ongoing allocation of CPU time, and that they are independent of any particular scheduling algorithm. The primary advantages that this independence confers are:
From the point of view of the guarantee system, the purpose of the scheduling hierarchy is to convert the guarantee representing 100% of the CPU (or the set of guarantees representing 100% of multiple CPUs) into the set of guarantees required by users, applications, and other resource consumers.
Each scheduler written for HLS is characterized by one or more mappings from an acceptable guarantee to a set of provided guarantees. Any guarantee that can be converted into a guarantee that is acceptable to a scheduler is also acceptable. For example, the start-time fair queuing (SFQ) scheduler can accept a proportional share guarantee, in which case it can provide proportional share guarantees to its children. It can also accept a proportional share with bounded error guarantee, in which cases it can provide that guarantee to its children. The guarantee representing 100% of the CPU is acceptable to the SFQ scheduler because it can be trivially converted into either kind of proportional share guarantee.
A hierarchy of schedulers and threads composes correctly if and only if (1) each scheduler in the hierarchy receives a guarantee that is acceptable to it and (2) each application thread receives a guarantee that is acceptable to it. The set of guarantees that is acceptable to a scheduler is an inherent property of that scheduling algorithm. The set of guarantees that is acceptable to an application depends partially on inherent characteristics of the application, and partially on other factors, such as the application’s importance.
The overall correctness of a scheduling hierarchy is established by starting at the root and working towards the children. If the scheduler at the root of a hierarchy receives the guarantee it was promised, and if each scheduler in the hierarchy correctly provides the guarantees that they have agreed to provide, then it is the case that all application threads will also receive the guarantees that they were promised.
The primary goal of the work on guarantees and scheduler composition is to ensure that each thread’s guarantees can be met in a system using hierarchical scheduling. Furthermore, when translating between guarantees, as little processor time as possible should be wasted; in other words, applications’ requirements should be met as efficiently as possible.
Two fundamental insights drive scheduler composition:
The compositional correctness of a scheduling hierarchy can be established off-line if the hierarchy will remain fixed. Correctness can also be established online by middleware such as the resource manager.
The guarantee system for scheduler composition can ensure that a hierarchy of schedulers and threads is correct in the sense that for each application that has received a guarantee, its scheduling requirements will be met. This correctness is contingent on the following assumptions:
So far, guarantees have been treated as abstract properties. In practice, however, guarantees are parameterized. For example, in the abstract a proportional share scheduler can provide a percentage of the CPU to a thread. In practice, a thread requires a specific percentage such as 10%.
To acquire this guarantee, a message is sent to the proportional share scheduler asking for a guarantee of 10% of the CPU. The scheduler uses its schedulability analysis routine to decide whether the guarantee is feasible or not. If it is, the request is accepted, otherwise it is rejected and no guarantee is provided. When a request for a guarantee is rejected, there are several courses of action that may be taken:
Guarantees are represented by identifiers of the following form:
TYPE [params]
Where TYPE represents the name of the kind of guarantee and [params] denotes a list of numeric parameters. The number of parameters is fixed for each kind of guarantee. Guarantee parameters are often in time units; for convenience, numeric parameters in this dissertation will be taken to be integers representing milliseconds unless otherwise noted.
Except in the special case of the uniformly slower processor guarantee, utilizations that appear as guarantee parameters are absolute, rather than relative. For example, if a proportional share scheduler that controls the allocation of 40% of a processor gives equal shares to two children, the guarantees that it provides have the type PS 0.2 rather than PS 0.5. Parameters in guarantees are in absolute units because this allows the meaning of each guarantee to be independent of extraneous factors such as the fraction of a processor controlled by the parent scheduler.
This section describes the formal properties of types of guarantees provided by multimedia schedulers.
The scheduler at the top of the hierarchy is given a guarantee of ALL, or 100% of the CPU, by the operating system. This guarantee has no parameters. Although it is tempting to parameterize this guarantee (and others) with a value indicating how much work can be done per time unit on a particular processor, Section 6.3.3.1 will present an argument that this type of parameterization is not practical in general.
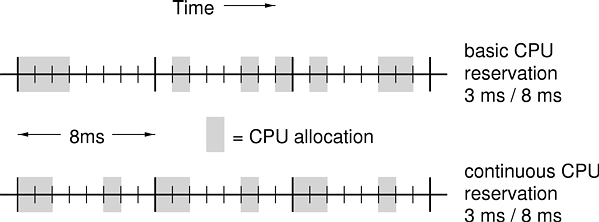
The CPU reservation is a fundamental real-time abstraction that guarantees that a thread will be scheduled for a specific amount of time during each period. Reservations are a good match for threads in real-time applications whose value does not degrade gracefully if they receive less processing time than they require. A wide variety of scheduling algorithms can be used to implement CPU reservations, and many different kinds of reservations are possible. The guarantee types for CPU reservations are:
The following list describes the properties of these kinds of CPU reservations. In particular, note that every CPU reservation is either basic or continuous, and either hard or soft, and that these properties are orthogonal.
|
A uniformly slower processor (USP) is a special kind of CPU reservation that was described in Section 2.3.1.4 . A USP guarantee has the form RESU r, where r is the fraction of the overall CPU bandwidth allocated to the USP. The granularity over which the reserved fraction of the CPU is to be received is not part of the guarantee, and must be specified dynamically. The guarantee provided by a uniformly slower processor is as follows. Given a virtual processor with guarantee RESU r, for any two consecutive deadlines dn and dn+1 that the child scheduler at the other end of the VP notifies the USP scheduler of, the VP is guaranteed to receive r(dn+1 - dn) units of CPU time between times dn and dn+1.
Proportional share (PS) schedulers are
quantum-based approximations of fair schedulers. Some PS schedulers
can guarantee that during any time interval of length t, a thread with a share s of the total processor bandwidth will receive at
least st - ![]() units of processor
time, where
units of processor
time, where ![]() is an error term that
depends on the particular scheduling algorithm. This guarantee is
called “proportional share bounded error” and has the
type PSBE s
is an error term that
depends on the particular scheduling algorithm. This guarantee is
called “proportional share bounded error” and has the
type PSBE s ![]() .
For the earliest eligible virtual deadline
first (EEVDF) scheduler [34],
.
For the earliest eligible virtual deadline
first (EEVDF) scheduler [34], ![]() is the length of the scheduling quantum. For
the start-time fair queuing (SFQ)
scheduler [28],
is the length of the scheduling quantum. For
the start-time fair queuing (SFQ)
scheduler [28], ![]() is more complicated to compute: it is a
function of the quantum size, the number of threads being scheduled
by the SFQ scheduler, and the share of a particular thread. Since
it is particularly well suited to hierarchical scheduling, we will
return to the SFQ scheduler in Sections 5.3.1.4
and 5.3.3
.
is more complicated to compute: it is a
function of the quantum size, the number of threads being scheduled
by the SFQ scheduler, and the share of a particular thread. Since
it is particularly well suited to hierarchical scheduling, we will
return to the SFQ scheduler in Sections 5.3.1.4
and 5.3.3
.
Some proportional share schedulers, such as the lottery scheduler [90], provide no deterministic performance bound to threads that they schedule. The guarantee given by this kind of PS scheduler is PS s, where s is the asymptotic share that the thread is guaranteed to receive over an unspecified period of time.
Since time-sharing schedulers make no particular guarantee to threads they schedule, they make the NULL guarantee, indicating strictly best-effort scheduling. Time-sharing schedulers usually attempt (but do not really guarantee) to avoid completely starving threads because starvation has been shown to lead to unbounded priority inversion when threads are starved while holding shared resources. Priority inversion is said to occur when a low-priority thread holds a resource, preventing a high-priority thread from running.
Most multilevel feedback queue time-sharing schedulers avoid starving threads because they are actually weak proportional share schedulers. The Windows 2000 scheduler (which is not proportional share) avoids starvation by increasing a thread’s priority to the maximum time-sharing priority if it is runnable but does not get to run for more than about three seconds. Both of these schedulers attempt to ensure that threads will not be starved as long as there are no high-priority “real-time” threads.
Time-sharing (TS) schedulers are designed to avoid starving threads that they schedule on a best-effort basis. However, TS schedulers will be unable to prevent starvation if the schedulers themselves are starved. It is therefore desirable to ensure that each time-sharing scheduler in a system receives a real (instead of best-effort) scheduling guarantee. This guarantee will ensure that (1) priority inversions caused by time-sharing threads being starved while holding resources do not occur, and (2) that the windowing system and associated administrative applications will remain responsive to user input regardless of the behavior of real-time applications in the system.
The set of guarantees presented in this chapter is by no means complete. Rather, it covers an interesting and viable set of guarantees made by multimedia schedulers that have been presented in the literature and that, together, can be used to meet the scheduling needs of many kinds of multimedia applications.
An additional guarantee type based on the time constraint abstraction provided by Rialto or Rialto/NT could be defined--time constraints guarantee a certain amount of CPU time before an application-specified deadline. However, this guarantee would be a dead-end with respect to conversion to other kinds of guarantees using schedulers and rewrite rules. Furthermore, the one-shot constraints violate our assumption that guarantees are long-lived entities.
An interesting guarantee would be one based on Mok and Chen’s multiframe tasks [63]. Multiframe tasks exploit patterns in applications’ CPU requirements in order to avoid making reservations based on worst-case requirements. This would be useful for applications such as the MPEG decoder, which exhibit large but somewhat predictable fluctuations in requirements between frames [8].
Recall that from the point of view of guarantees, the purpose of the scheduling hierarchy is to convert the ALL guarantee(s) into the set of guarantees required by users, applications, and other resource consumers. The remainder of this chapter describes the two ways that guarantees can be converted into other guarantees. First, each scheduler in the hierarchy requires a guarantee, and provides guarantees to other schedulable entities through virtual processors. Second, guarantee rewrite rules can be used to convert guarantees without using a scheduler to perform the conversion.
Table 5.1 shows a number of schedulers and what guarantee(s) they can provide. The top six schedulers have been implemented in HLS; the remaining schedulers have been described in the literature. The table is to be interpreted as follows:
Sections 5.3.1.1 through 5.3.1.7 discuss and justify the guarantee conversions listed in Table 5.1.
|
A preemptive, fixed-priority scheduler that uses admission control to schedule only one virtual processor at each priority gives no guarantee of its own: rather, it passes whatever guarantee it receives to its highest-priority child. All other children receive the NULL guarantee.
This logic can be seen to be correct by observing that no other virtual processor can create scheduling contention for the highest-priority VP when a preemptive fixed-priority scheduler is in use. No guarantee can be given to lower-priority VPs because the one with the highest priority may be CPU-bound.
Most uniprocessor schedulers register a single virtual processor with their parent, and multiplex CPU time received from that virtual processor among multiple children. The join scheduler performs the opposite function: it registers multiple virtual processors with its parents and schedules its child VP any time any of the parents allocates a physical processor to it. This allows the scheduling hierarchy to be generalized to a directed acyclic graph.
Join schedulers function as OR gates in the scheduling hierarchy: they schedule their child virtual processor when receiving CPU time from any parent. The synthesis of complex scheduling behaviors from collections of small, simple schedulers often requires the use of join schedulers. For example, as Section 6.2.1 illustrates, a scheduler that provides hard CPU reservations can also be used to provide soft CPU reservations using join schedulers. The purpose of a join scheduler, as in the preceding example, is usually to direct slack time in the schedule to a virtual processor that can make use of it. For this reason, a join scheduler will usually be joining a guarantee such as a CPU reservation with a NULL guarantee (since slack time in the schedule is, by definition, not guaranteed). Even so, the rest of this section will present the exact rules for the guarantees that a join scheduler can provide, which were too complicated to present in Table 5.1 .
An entity scheduled by a join scheduler may pick any one of its parent guarantees to take, with the restriction that if the guarantee that it picks is a hard guarantee, it must be converted into the corresponding soft guarantee. To see that this is correct, notice that a join scheduler cannot give a virtual processor any less CPU time than the VP would have received if it were directly given any of the join scheduler’s parent guarantees. However, the join scheduler may cause a virtual processor to receive additional CPU time, meaning that it cannot give a hard guarantee.
On a uniprocessor machine, guarantees of the same type (or guarantees that can be converted into the same type) may be added together. For example, if a join scheduler receives guarantees of RESBS 2 30 and RESBS 3 30, then the join scheduler can provide a guarantee of RESBS 5 30. Clearly this is more complicated when the reservations have different periods. We do not work out this case in detail since it is difficult to picture this situation coming up in practice--it would be simpler and more efficient to simply have a single scheduler give the thread the guarantee that it needs. Guarantees cannot be added on a multiprocessor machine because the join scheduler may be scheduled by multiple parents at the same time, and it can make use of at most one. To address this case, multiprocessor join schedulers must have a method for deciding from which parent to accept a physical processor. For example, a join scheduler could assign unique numbers to its parents and always release any processors granted from parents other than the highest-numbered parent that grants a processor.
Limit schedulers can be used to convert a soft guarantee into a hard one. A limit scheduler that is given a guarantee of a basic, soft CPU reservation would, like a reservation scheduler, keep track of the amount of CPU time that it has allocated to its (single) child virtual processor during each period. However, when its child is about to receive more than the guaranteed amount, it releases the processor and does not request it again until the start of the next period.
The PS scheduler that was implemented for HLS
implements the start-time fair queuing
(SFQ) algorithm with a warp extension
similar to the one in BVT [20]. When the warp of all
virtual processors is zero, it behaves as an SFQ scheduler. Goyal
et al. showed that an SFQ scheduler provides fair resource
allocation in a hierarchical scheduling environment where it does
not receive the full CPU bandwidth. This result was derived in the
context of network scheduling [28] and has also been
applied to CPU scheduling [27]. Therefore, the
conversion PS
![]() PS+ is
justified. They also showed that when an SFQ scheduler is scheduled
by a fluctuation constrained (FC)
server, then the entities scheduled by the SFQ scheduler are also
FC servers.
PS+ is
justified. They also showed that when an SFQ scheduler is scheduled
by a fluctuation constrained (FC)
server, then the entities scheduled by the SFQ scheduler are also
FC servers.
We now show that an FC server is the same as the
PSBE
(proportional share bounded error) guarantee. Following the
notation in Lee [47, p. 127], an FC
server is characterized by two parameters (s, ![]() ). Informally,
s is the average share guaranteed to a
virtual processor and
). Informally,
s is the average share guaranteed to a
virtual processor and ![]() is the
furthest behind the average share it may fall. Let C(t) denote the
instantaneous service delivered by a processor. For any times a and b with
a < b
is the
furthest behind the average share it may fall. Let C(t) denote the
instantaneous service delivered by a processor. For any times a and b with
a < b
|
|
(5.1) |
Let q be the
scheduler quantum size and T be the
total number of threads being scheduled by a SFQ scheduler, with
rf being the weight (the fraction of the total
number of shares) assigned to thread f. Then, if an SFQ scheduler is scheduled by an FC
server with parameters (s, ![]() ), each of the threads scheduled by the
SFQ scheduler is also a FC server with parameters calculated as
follows:
), each of the threads scheduled by the
SFQ scheduler is also a FC server with parameters calculated as
follows:
|
|
(5.2) |
Theorem 5.1. Any proportional share scheduler can be scheduled correctly by (1) a continuous CPU reservation whose period is equal to the size of the scheduling quantum, or (2) a uniformly slower processor by treating the end of each scheduling quantum as a deadline.
Informal proof.
Since the time quantum of a PS scheduler determines its minimum
enforceable scheduling granularity, the scheduler will function
correctly as long as it receives a guaranteed amount of CPU time
during each quantum. This can be accomplished by assigning to the
PS scheduler a continuous CPU reservation with period equal to the
quantum size, or scheduling it using a USP and treating the end of
each period as a deadline. ![]()
This result is of limited use in real systems because the subdivision of scheduling quanta will result in fine-grained time slicing among different reservations or USPs. The purpose of scheduling quanta is to limit the number of context switches in a system. Therefore, fine-grained time slicing defeats the purpose of scheduling quanta.
Rez, the CPU reservation scheduler that was implemented for HLS, must be run at the root of the scheduling hierarchy unless it receives a RESU guarantee. It is capable of making use of such a guarantee because it is deadline-based, and consequently can make deadline information available to a uniformly slower processor scheduler.
Since a time-sharing scheduler does not make any guarantee to entities that it schedules, it can make use of any guarantee. More precisely, it requires a NULL guarantee, to which any other guarantee may be trivially converted.
This section explains and justifies the guarantee conversions for the schedulers listed in the bottom part of Table 5.1 .
The BSS-I [51] and PShED [52] schedulers provide uniformly slower processors to other schedulers. Any scheduler that has a run-time representation of its deadlines may use a uniformly slower processor.
The borrowed virtual time (BVT) scheduler [20] has not been shown to be capable of providing any reservation-like guarantee. It gives each thread a warp parameter that allows it to borrow against its future CPU allocation; this has the useful property of decreasing average dispatch latency for threads with high warps. Warp, in combination with two additional per-thread scheduler parameters warp time limit and unwarp time requirement, defeats PS analysis techniques that could be used to prove that BVT provides bounded allocation over a specific time interval. However, despite the additional scheduling parameters, BVT (1) limits the CPU allocation of each thread to its share (over an unspecified time interval) and (2) supports hierarchical scheduling in the sense that it only increases a thread’s virtual time when it is actually running. Therefore, BVT is capable of splitting a PS guarantee into multiple PS guarantees.
The constant bandwidth server (CBS) [2] provides the same scheduling behavior as a basic, hard reservation. Since it is deadline based, it can be scheduled by a uniformly slower processor.
The earliest eligible deadline first (EEVDF) algorithm [85] was shown to provide proportional share scheduling with bounded error. It has not been shown to work when given less than the full processor bandwidth.
The Linux scheduler is a typical time-sharing scheduler that provides no guarantees.
Lottery and Stride scheduling [90] provide proportional share resource allocation but do not bound allocation error. They have been shown to work correctly in a hierarchical environment.
The scheduler in the Portable Resource Kernel [68] was designed to be run as a root scheduler, and can provide both hard and soft CPU reservations. Although it is based on rate monotonic scheduling, it must have an internal representation of task deadlines in order to replenish application budgets. Therefore, it could be adapted to be scheduled using a uniformly slower processor.
Rialto [40] and Rialto/NT [37] are reservation schedulers. They could be adapted to be scheduled using a USP because they have an internal representation of their deadlines.
SFS [15] is a multiprocessor proportional share scheduler. It does not provide bounded allocation error to entities that it schedules.
The Spring operating system [82] uses a deadline-based real-time scheduler to provide hard real-time guarantees to tasks that it schedules. Since it is deadline-based, it can make use of a USP.
The total bandwidth server (TBS) [79] provides soft CPU reservations: it guarantees that a minimum fraction of the total processor bandwidth will be available to entities that it schedules, but it can also take advantage of slack time in the schedule to provide extra CPU time. It is deadline-based, and consequently can be scheduled using a USP.
The Windows 2000 time-sharing scheduler requires and provides no guarantees.
Rewrite rules exploit the underlying similarities between different kinds of soft real-time scheduling. For example, it is valid to convert any CPU reservation with amount x and period y to the guarantee PS x/y. This conversion means that any pattern of processor allocation that meets the requirements for being a CPU reservation also meets the requirements for being a PS guarantee. Clearly, the reverse conversion cannot be performed: a fixed fraction of the CPU over an unspecified time interval is not, in general, equivalent to any particular CPU reservation.
Table 5.2 shows which guarantees can be converted into which others using rewrite rules. Characters in the matrix indicate whether the guarantees listed on the left can be converted to the guarantees listed on the bottom. Feasible conversions are indicated by “t,” while impossible conversions are indicated by “f.” When a conversion or lack of conversion is non-trivial, the accompanying number refers to a theorem from this section.
|
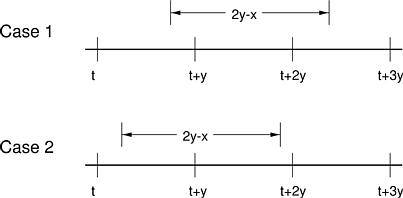
Lemma 5.1. Given a thread with guarantee RESBH x y or RESBS x y, every time interval (2y -x) units long contains at least x units of CPU time. Furthermore, any time interval smaller than this is not guaranteed to contain at least x units of CPU time.
|
We show that an interval of length 2y - x is necessary by contradiction. Assume that there
exists an 0 < ![]() < x such that
every time interval of length 2y - x -
< x such that
every time interval of length 2y - x - ![]() contains at least x units of CPU time.
Without loss of generality we examine the time interval [t, t + 2y]
where t is the time chosen by the
scheduler in the definition of basic CPU reservation in
Section 5.2.2.2
. Furthermore, assume that the basic
reservation scheduler allocates CPU time to the reservation during
time intervals [t, t + x] and [t + 2y - x, t + 2y]. In
other words, it allocates CPU time at the beginning of the first
period and the end of the second, as Figure 5.3illustrates.
Then during the time interval [t +
x, t + 2y
-
contains at least x units of CPU time.
Without loss of generality we examine the time interval [t, t + 2y]
where t is the time chosen by the
scheduler in the definition of basic CPU reservation in
Section 5.2.2.2
. Furthermore, assume that the basic
reservation scheduler allocates CPU time to the reservation during
time intervals [t, t + x] and [t + 2y - x, t + 2y]. In
other words, it allocates CPU time at the beginning of the first
period and the end of the second, as Figure 5.3illustrates.
Then during the time interval [t +
x, t + 2y
- ![]() ] the
reservation will have been scheduled for x -
] the
reservation will have been scheduled for x - ![]() time units, contradicting our assumption that
every time interval 2y - x -
time units, contradicting our assumption that
every time interval 2y - x - ![]() units long
contains at least x units of CPU
time.
units long
contains at least x units of CPU
time. ![]()
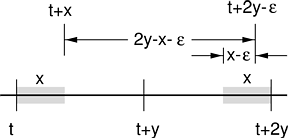
|
The following theorem shows that basic CPU reservations can be converted into continuous CPU reservations.
Theorem 5.2. The guarantees RESBS x y and RESBH x y can each be converted into the guarantee RESCS x (2y - x + c) for any c > 0.
The following theorem proves that it is not possible to convert an arbitrary basic CPU reservation into a continuous, hard CPU reservation. The only basic CPU reservation that is also a hard, continuous CPU reservation is the trivial basic reservation that is equivalent to ALL.
Theorem 5.3. Neither RESBS x y nor RESBH x y can be converted into a continuous, hard CPU reservation unless x = y.
The next lemma will be used in the proof that continuous CPU reservations can be converted into proportional share guarantees with bounded error.
Lemma 5.2. The longest time interval during which a thread with guarantee RESCS x y or RESCH x y can be starved is y - x units long.
The following theorem establishes a correspondence between continuous CPU reservations and proportional share guarantees with bounded error.
The next lemma will be used to prove that basic CPU reservations can be converted into proportional share guarantees with bounded error.
Lemma 5.3. The longest time interval during which a thread with guarantee RESBS x y or RESBH x y can be starved is 2(y - x) units long.
The following theorem establishes a correspondence between basic CPU reservations and proportional share guarantees with bounded error.
The next theorem proves that any CPU reservation may be converted into a proportional share guarantee.
Theorem 5.6. Any CPU reservation, whether hard or soft, basic or continuous, with amount x and period y may be converted into the guarantee PS x/y.
The following theorem was motivated by an observation by Stoica et al. [84], who said it is possible to provide reservation semantics using a proportional share scheduler.
Theorem
5.7. The guarantee PSBE s ![]() can, for any y >
can, for any y > ![]() , be converted into the guarantee RESCS (ys
-
, be converted into the guarantee RESCS (ys
- ![]() ) y or RESBS (ys
-
) y or RESBS (ys
- ![]() ) y.
) y.
Theorems 5.4 , 5.5 , and 5.7 show that CPU reservations can be converted into proportional share guarantees with bounded error and vice versa. The abstraction underlying all of these guarantees--a minimum allocation of CPU time over a specified time interval--is necessary for real-time scheduling to occur.
The conversions are useful when combined with the results that were proved about hierarchical SFQ schedulers. Recall that if a SFQ scheduler receives a PSBE guarantee it also provides this type of guarantee to its children. Therefore, a reservation scheduler can be used at the root of the scheduling hierarchy to schedule applications whose threads require precise or fine-grained scheduling, as well as giving a reservation to an instance of the SFQ scheduler. The reservation can be converted into a PSBE guarantee that is useful to the SFQ scheduler, which can then give performance guarantees to entities that it schedules.
There is a good reason not to use a proportional share scheduler as the root scheduler in a system, even though PS schedulers that have bounded allocation error are perfectly capable of providing CPU reservations. The reason is that while these schedulers bound allocation error, they do not bound allocation error within a period of a thread’s choosing. To see this, let us first look at SFQ.
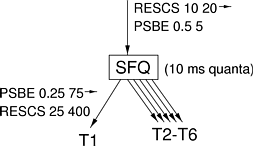
Consider an SFQ scheduler that uses a quantum
size of 10 ms (a common quantum size in a general-purpose operating
system) and receives a guarantee of RESCS 10 20. It schedules 6 threads, T1-T6.
T1 has weight 0.5 and T2-T6 each have weight 0.1. This scheduler is
depicted in Figure 5.4
.Applying Theorem 5.4, the SFQ
scheduler’s guarantee can be converted to the guarantee PSBE ![]()
![]() , or PSBE 0.5 5. Using Equation 5.2, the thread
with weight 0.5 can be shown to have a guarantee of PSBE
, or PSBE 0.5 5. Using Equation 5.2, the thread
with weight 0.5 can be shown to have a guarantee of PSBE ![]()
![]() , or
PSBE
0.25 75. By Theorem 5.7
, this guarantee can be
converted to RESCS
(400 . 0.25 - 75) 400, or
RESCS 25 400.
, or
PSBE
0.25 75. By Theorem 5.7
, this guarantee can be
converted to RESCS
(400 . 0.25 - 75) 400, or
RESCS 25 400.
This reservation is highly pessimistic: instead of being guaranteed to receive 25% of the CPU (its long-term average share), T1 is only guaranteed to receive 6.25% of the CPU during any given 400 ms period. In order to bring the level of pessimism down to 10% the reservation period y would have to be 3000 ms, or 3 s--far too long a deadline for most multimedia applications. This example illustrates a serious shortcoming of SFQ: it has delay bounds that are proportional to the number of threads that it is scheduling. In a typical time-sharing system with dozens of threads the kind of performance guarantee given to threads by an SFQ scheduler would not be useful for scheduling multimedia applications.
EEVDF [34] has a tighter error bound than SFQ: allocation error is bounded to the length of a single scheduling quantum. This bound is optimal in the sense that no quantum-based scheduler can have a lower error. To see the consequences of the EEVDF error bound, assume that a thread in a video application requires a guarantee of 5 ms / 33 ms in order to display 30 frames per second, and that we want to provide this reservation using an EEVDF scheduler. Assume that the EEVDF scheduler uses a 10 ms time quantum and is at the root of the scheduling hierarchy where it receives a guarantee of ALL.
The guarantee provided by the EEVDF scheduler
will have the form PSBE s ![]() ,
where
,
where ![]() =10 ms. To construct a
CPU reservation with period 33 ms from the PSBE guarantee we use
Theorem 5.7
, which states that the
guarantee PSBE s
=10 ms. To construct a
CPU reservation with period 33 ms from the PSBE guarantee we use
Theorem 5.7
, which states that the
guarantee PSBE s ![]() can be converted into a soft, continuous CPU reservation with
amount (ys -
can be converted into a soft, continuous CPU reservation with
amount (ys - ![]() ) and period y for any y
>
) and period y for any y
> ![]() . Combining this conversion with the PSBE guarantee, we can deduce that
the reservation amount (ys -
. Combining this conversion with the PSBE guarantee, we can deduce that
the reservation amount (ys - ![]() ) will
be (33s -
10), which must equal 5 ms. This constrains the value of s to be
) will
be (33s -
10), which must equal 5 ms. This constrains the value of s to be ![]() , or
0.45.
, or
0.45.
Therefore, providing a CPU reservation of 5 ms / 33 ms, or 15% of the CPU, using EEVDF requires allocating 45% of the processor bandwidth when the EEVDF scheduler uses a 10 ms quantum. Clearly, this degree of over-reservation is not acceptable in general. EEVDF’s error bounds are optimal, so it is impossible for a different proportional share scheduler to do better than this. To reduce the level of pessimism, the only parameter available to adjust is the scheduler quantum size.
Assume that 10% is the largest degree of
pessimism that is acceptable for the video player reservation. This
means that s, the share of the CPU
reserved for the thread, must be no more than 1.1(5/33), or 16.7% of
the CPU. So, we assume that the EEVDF scheduler provides the
guarantee PSBE 0.167 ![]() and we need to solve for a value of
and we need to solve for a value of ![]() that allows the PSBE guarantee to be converted into
the guarantee RESCS 5
33. To do this we apply Theorem 5.7
backwards: we know that x must be 5 ms and y must be 33 ms; this tells us that 5 =
(33)(0.167) -
that allows the PSBE guarantee to be converted into
the guarantee RESCS 5
33. To do this we apply Theorem 5.7
backwards: we know that x must be 5 ms and y must be 33 ms; this tells us that 5 =
(33)(0.167) - ![]() . Solving for
. Solving for ![]() , we find that the required scheduling
quantum is 0.5 ms.
, we find that the required scheduling
quantum is 0.5 ms.
Since EEVDF is an optimally fair PS scheduler, it will context switch between threads every 0.5 ms even when there are no real-time applications in the system. This will cause unacceptable inefficiency for threads that make use effective use of the cache. As we will show in Section 10.3.3 , on a 500 MHz Pentium III a thread whose working set is 512 KB, the same size as the level-two cache, can take more than 2 ms to re-establish its working set in the cache after a context switch. Clearly, if context switches occur every 0.5 ms, applications with large working sets will not benefit from the cache.
These calculations indicate that proportional share schedulers are not suitable for providing CPU reservations to applications whose periods are of the same order of magnitude as the scheduler quantum size. We conclude that EDF- or static-priority-based reservation schedulers should be used to schedule applications with precise, fine-grained real-time requirements.
A hierarchy of schedulers composes correctly only if each scheduler in the hierarchy receives an acceptable guarantee, or a guarantee that can be converted into an acceptable guarantee. This chapter has (1) described the guarantee mechanism and how it can be used, (2) described the sets of guarantees that are acceptable and provided by a number of multimedia schedulers, and (3) shown which guarantees can be converted into which other guarantees, including proofs of the conversions when necessary.