Chapters 4 and 9 established the overall feasibility of HLS in a general-purpose operating system by describing its design and a prototype implementation. This chapter provides additional support for the feasibility of HLS by showing that the run-time cost of flexible scheduling is modest. This chapter also supports the usefulness of HLS by providing quantitative data about two scheduling hierarchies whose scheduling behavior cannot be achieved using a traditional time-sharing scheduler.
All performance tests were run on a dual Pentium III 500 MHz that, unless otherwise stated, was booted in uniprocessor mode. The test machine had 256 MB of memory and was equipped with an Intel EEPro 10/100 network interface and a 36 GB ultra fast wide SCSI disk.
The duration of brief events was measured using the Pentium timestamp counter by executing the rdtsc instruction. This instruction returns a 64-bit quantity containing the number of cycles since the processor was turned on. On a 500 MHz processor, the timestamp counter has a resolution of 2 ns.
All confidence intervals in this chapter were calculated at 95%.
Table 10.1
shows times taken to perform
a variety of HLS operations from user level. That is, the total
elapsed time to perform the given operation including: any
necessary user-space setup, trapping to the kernel, checking
parameters and copying them into the kernel, performing the
operation, and returning to user level. These costs are incurred
during mode changes: when an application starts, ends, or changes
requirements, rather than being part of ordinary scheduling
decisions. Nevertheless, besides loading and unloading a scheduler
HLS operations are cheap: they all take less than 40 ![]() s on a 500 MHz CPU.
s on a 500 MHz CPU.
Except for loading and unloading a scheduler, which uses native Windows 2000 functionality, all HLS services are accessed through the HLSCtl system call. Due to cache effects and dynamic binding of the dynamic link library (DLL) containing kernel entry points, the first few times each operation was performed took highly variable amounts of time. To avoid measuring these effects, each operation was performed 60 times and the first 10 results were thrown away, leaving 50 data points.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Creating a scheduler instance requires the following actions to be performed: allocating a block of memory for per-instance data, adding the scheduler to a global list of scheduler instances, and initializing data structures used to provide a timer to the scheduler. The new instance is then ready to be used, but it is not part of the scheduling hierarchy until it registers one or more virtual processors with another scheduler. Destroying a scheduler involves removing it from the global list of scheduler instances and deallocating its data block.
All threads, when created, belong to a default time-sharing scheduler. They may move, or be moved, to a different scheduler at a later time in order to receive a different scheduling behavior. Moving a thread involves releasing the processor if the thread is in the ready or running states, unregistering the thread’s bottom scheduler’s virtual processor from the current scheduler, registering the virtual processor with the new scheduler, and then requesting scheduling if the thread was previously in the ready or running state.
Beginning and ending a CPU reservation is equivalent to moving a thread from its current scheduler to a reservation scheduler and then requesting a CPU reservation. Ending a reservation moves the thread back to the original scheduler. There are two cases for beginning and ending a CPU reservation. In the first case, the thread that is requesting a CPU reservation belongs to the same process as the thread that will receive the CPU reservation. In the second case, the two threads belong to different processes. The first case is faster since within a process, a handle to the target thread will be known. Handles are reference-counted indirect pointers to Windows 2000 kernel objects; their scope is a single process. When a request is made to begin or end a CPU reservation for a thread in a different process, a handle must be acquired using the OpenThread call before the request is made, and this takes time. OpenThread returns a handle when given a thread ID, a global name for a thread.
The previous section described HLS operations that are not performed often, compared to the frequency of individual scheduling decisions. Since scheduling decisions are implicit, or not directly requested by threads, it is more difficult to accurately measure their costs compared to the operations in the previous section. The strategy taken in this section is to measure the effect of HLS on context switch time--the time between when one thread stops running and another thread starts. Context switches occur when a thread blocks and, potentially, when a thread unblocks. They also occur at scheduler-determined times: for example, a quantum-based scheduler such as a proportional share scheduler or a traditional time-sharing scheduler preempts a thread when its quantum expires in order to run a different thread.
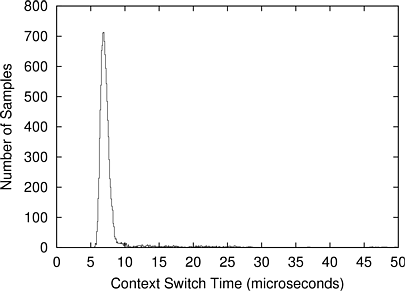
Table 10.2 shows the effect that HLS has on thread context switch times. These numbers were calculated by running a test application that created ten threads and let them run for 100 seconds. Each of the threads continuously polled the Pentium timestamp counter in order to determine when the thread was running and when it was not. By collating the execution traces of all ten threads it was possible to find the durations of the time intervals between when one thread stopped running and when another started. This time, which was not available to any thread because it was spent in the kernel, is the context switch time. The scheduling hierarchy used to generate these figures had two levels: a fixed-priority scheduler at the root of the scheduling hierarchy that scheduled a reservation scheduler at high priority and a time-sharing scheduler at low priority.
|
||||||||||||||||||||||||||||||
The released version of Windows 2000 is the kernel binary that would be installed by an off-the-shelf copy of Windows 2000. The rebuilt version of Windows 2000 is a kernel compiled from unmodified sources. The context switch time for the released kernel is slightly faster than the context switch time for the rebuilt kernel because post-compilation optimizations are applied to released Windows 2000 kernels--these are not available as part of the Windows source kit.
For the experiment used to generate each median context switch time reported in Table 10.2, all threads belonging to the test application were scheduled by the same scheduler. This indicates that context switches within a well-written HLS scheduler are about 60-70% more expensive than context switches in the rebuilt version of Windows 2000. The proportional share scheduler cannot be considered to be well written: it is considerably less efficient than the other schedulers since it uses a naive linear search (among all threads, not just runnable ones) when searching for a thread to dispatch. The performance of this scheduler could be improved by scanning only runnable threads and/or using a sub-linear search algorithm.
The impact of increased context switch time on overall application throughput depends heavily on how many context switches applications incur. For example, multimedia applications that on average run for 1 ms before being context switched incur 0.71% overhead from the native Windows 2000 scheduler, and 1.25% overhead from the HLS reservation scheduler. This overhead is likely to be acceptable for home and office machines where high throughput is not critical; it may not be acceptable for server machines. However, there are a number of optimizations that could be applied to HLS in order to improve context switch time--these are discussed in Section 10.6 . Furthermore, in Section 10.3.3 we will show that the true cost of context switches, including the time lost to applications as they rebuild their working sets in the cache, can be much higher than the numbers presented in this section.
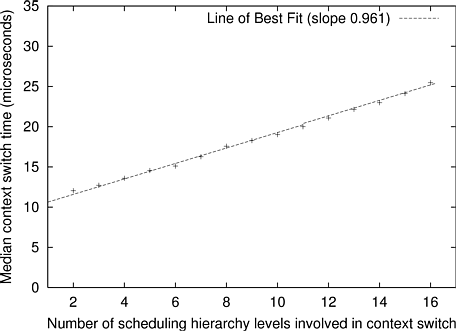
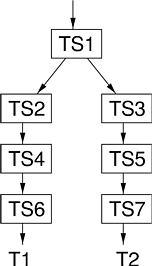
The previous section measured the cost of context switches involving a scheduling decision made by a single HLS scheduler. This section measures the effect of varying the number of schedulers involved in a scheduling decision. Figure 10.2 shows the scheduling hierarchy that was used to measure the context switch time of a 4-level scheduler. Assume that TS1 has allocated the CPU to TS2, allowing T1 to run. At the end of TS2’s time slice, TS1 revokes the processor from TS2; the revocation proceeds down the chain until it reaches T1, whose bottom scheduler releases the processor. Once the release notifications propagate back to TS1, it grants the processor to TS3; once the grant notifications propagate to T2, a scheduling decision has been made. Analogous hierarchies were used to measure the cost of context switches for hierarchies of other depths.
|
Figure 10.3 shows how context switch time varies with hierarchy depth. The increase in cost is nearly linear. The slope of the line of best fit is 0.961, meaning that each additional level of the scheduling hierarchy adds approximately 961 ns to the context switch time. In practice it is unlikely that a scheduling hierarchy 16 levels deep would ever be needed--the complex scenarios in Chapter 7 required at most five levels.
This section presents data supporting the view that the true cost of a context switch can be much larger than the cost of executing the context switch code path in the kernel, because a newly-running thread may be forced to re-establish its working set in the processor cache. This argument is relevant to the feasibility of HLS because increased context switch costs can hide overhead caused by hierarchical scheduling--a subject we will return to at the end of this section.
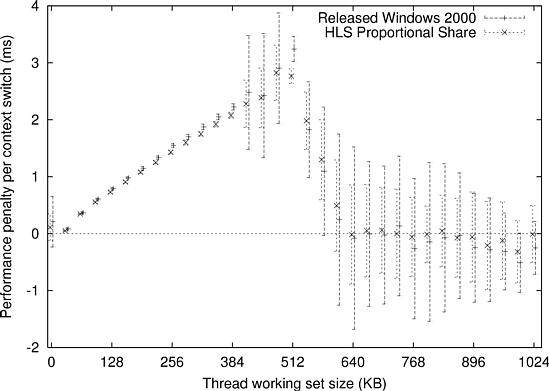
Figure 10.4 shows the results of an experiment designed to measure this effect. The independent variables in this experiment are the sizes of threads’ working sets and the scheduler that the threads belong to. Schedulers used in this experiment were the released version of the native Windows 2000 scheduler and the HLS proportional share scheduler--these were the schedulers with the shortest and longest median context switch times in Table 10.2.
The work performed by each thread was to repeatedly cycle through a working-set-sized array by reading the value of an array location, performing a simple operation on it, and then writing the result back into the array. Since the level two (L2) cache on the Pentium III processor used for this experiment is 512 KB, a thread with working set size of 512 KB could be said to be making maximally effective use of the cache. The data points in Figure 10.4 represent working sets of sizes 0 KB through 1024 KB, in 32 KB increments. The data points for the two schedulers are offset slightly in the figure only to allow their error bars to be seen clearly: adjacent points represent identical working set sizes.
To generate each data point and the associated error bar, the amount of work performed by a single thread with a given working set size was compared with the aggregate amount of work performed by ten threads, each having a working set of the same size. The time-sharing schedulers caused context switches when the ten threads were running but not when one thread was running. The difference between the work performed by one and ten threads was assumed to be caused by context switch overhead. Let T be the amount of time the threads ran for, W1 be the amount of work performed by one thread during the experiment, W10 be the total amount of work performed by ten threads, and N10 be the number of context switches between the ten threads. Then, the following equation describes the performance penalty C per context switch:
|
|
(10.1) |
Another artifact of Figure 10.4 that we do not have a good explanation for is the fact that in the 32 KB-384 KB range, the performance penalty per context switch is slightly larger for the released Windows 2000 scheduler than it is for the HLS proportional share scheduler. This is almost certainly not due to a difference in the schedulers, but may again be caused by page coloring and TLB effects.
For working sets between 32KB and 384KB, the
increase in thread performance penalty is very close to being
linear in the size of threads’ working sets. A line of best
fit through the points in this region of the graph indicates that
each additional KB of working set size increases the context switch
performance penalty of a thread by 5.57 ![]() s. If it takes the processor
5.57
s. If it takes the processor
5.57 ![]() s
to read 1 KB of data, 179 MB can be read in one second. This number
is in the same order of magnitude as the memory bandwidth that the
Stream Benchmark [57] reports on the test
machine: 315 MB/s.
s
to read 1 KB of data, 179 MB can be read in one second. This number
is in the same order of magnitude as the memory bandwidth that the
Stream Benchmark [57] reports on the test
machine: 315 MB/s.
If we take the additional cost of a HLS context
switch to be the difference between the median context switch time
for the rebuilt Windows 2000 kernel and the median context switch
time for the HLS time-sharing scheduler, 4.35 ![]() s, then this cost is
exceeded by the context switch performance penalty by an order of
magnitude when each thread has a working set size of 8 KB or more,
and it is exceeded by two orders of magnitude when threads have
working sets of 79 KB or more. Furthermore, for threads whose
working set is the same size as the L2 cache, the performance
penalty of re-establishing the working set can be almost 3 ms--an
enormous penalty when compared to the in-kernel context switch cost
on the order of 10
s, then this cost is
exceeded by the context switch performance penalty by an order of
magnitude when each thread has a working set size of 8 KB or more,
and it is exceeded by two orders of magnitude when threads have
working sets of 79 KB or more. Furthermore, for threads whose
working set is the same size as the L2 cache, the performance
penalty of re-establishing the working set can be almost 3 ms--an
enormous penalty when compared to the in-kernel context switch cost
on the order of 10 ![]() s.
s.
In 1991 Mogul and Borg [62] showed that the cache performance cost of a context switch could dominate overall context switch performance. Furthermore, they speculated that in the future the increasing cost of memory accesses in terms of CPU cycle times would make the impact of the cache performance part of context switch cost increasingly dominant. They appear to have been correct.
The HLS prototype achieves fine-grained
scheduling by increasing the frequency of the periodic clock
interrupt in Windows 2000. The default clock interrupt frequency of
the hardware abstraction layer (HAL) used by HLS is 64 Hz, with
frequencies up to 1024 Hz supported. At 64 Hz the minimum
enforceable scheduling granularity is 15.6 ms, and at 1024 Hz it is
just under 1 ms. We modified HALMPS--the default HAL for
multiprocessor PCs--to add support for increasing the clock
frequency to 8192 Hz, achieving a minimum enforceable scheduling
granularity of about 122 ![]() s.
s.
Table 10.3 shows the overhead caused by clock interrupts as a function of frequency. These numbers were taken by measuring the throughput of a test application that was allowed to run for ten seconds at each frequency. Twenty repetitions of the experiment were performed. The “warm cache” workload touched very little data, and therefore when the clock interrupt handler ran, its code and data were likely to be in the L2 cache of the Pentium III. The “cold cache” workload consisted of performing operations on an array 512 KB long (the same size as the L2 cache) in an attempt to flush the clock interrupt instructions and data out of the L2 cache.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
This experiment shows that application slowdown due to high-frequency clock interrupts is not severe. Even so, a precisely settable interrupt facility would be a desirable feature in Windows 2000 since it would allow microsecond-accurate interrupts that do not cause any overhead when the interrupts are not required. Since HALMPS uses the real-time clock--a hardware device found on all modern PC motherboards--to generate clock interrupts, the advanced programmable interrupt controller (APIC)--another device found on all modern PCs--is left unused and a device driver could be written that uses the APIC to provide precise interrupts. This has been done for other general-purpose operating systems such as Linux [80].
Previous sections in this chapter argued that HLS is feasible. This section demonstrates the usefulness of HLS by presenting quantitative data about the performance of application threads being scheduled using HLS. In each of the two examples in this section, HLS schedulers are used to provide scheduling behaviors that cannot be provided using a traditional time-sharing scheduler. In other words, we show quantifiable benefits from sophisticated schedulers. Various schedulers that have been presented in the literature can provide one or the other of the scheduling behaviors described in these scenarios, but very few can provide both of them.
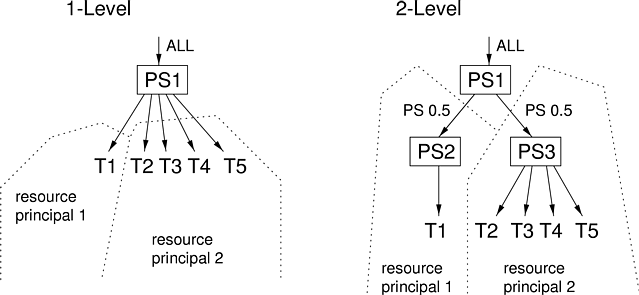
Hierarchical isolation of resource principals can be desirable when a machine is shared between users, administrative domains, or accounting domains. Figure 10.5shows two scheduling hierarchies. The single-level scheduling hierarchy on the left is analogous to the schedulers in general-purpose operating systems: it considers each individual thread to be a resource principal, and allocates processor time to them accordingly. The scheduler on the right allocates a fair share of the processor to each of two resource principals.
|
Table 10.4 presents performance data gathered over 10-second runs using scheduling hierarchies like the ones depicted in Figure 10.5 . The number of threads belonging to resource principal 1, N1, is always equal to one in this experiment. The total fraction of the CPU allocated to the thread belonging to resource principal 1 is %1. Similarly, N2 is the number of threads belonging to resource principal 2 and %2 is the total amount of CPU time allocated to them.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
The bottom part of Table 10.4 confirms that when threads belonging to principals 1 and 2 are assigned to separate schedulers, each of which is given a proportional share guarantee, principal 2 cannot cause a thread belonging to principal 1 to be starved. For example, even when there are 256 CPU-bound threads that belong to principal 2, principal 1 receives approximately 50% of the CPU. This is the desired behavior. There is an apparent trend towards the bottom of Table 10.4 for principal 2 to receive slightly less than half of the CPU time; for example, 49.8% of the total for the 256-thread case. This is caused by overhead in principal 2’s proportional share scheduler, which, as we mentioned in Section 10.3 , is not implemented efficiently. Also, principal 1 is not receiving more than 50% of the total amount of CPU time, but rather, is performing more than 50% of the total amount of work done by both principals.
Time-sharing schedulers on general-purpose operating systems can effectively schedule a single real-time application along with interactive and background tasks by running the real-time task at the highest priority. However, this simple method fails when the real-time application contains CPU-bound threads. The frame rendering loops in virtual environments and simulation-based games are CPU-bound because they are designed to adaptively provide as many frames per second (FPS) as possible; this makes it effectively impossible for them to gracefully share the processor with background applications when scheduled by a traditional time-sharing scheduler.
In the experiment described in this section, a synthetic test application is used instead of an actual application because the test application is self-monitoring: it can detect and record gaps in its execution, allowing the success or failure of a particular run to be ascertained. The situation described here is real, however, and anecdotal experience suggests that to successfully run a game under Windows 2000 using the default priority-based scheduler, it is necessary to avoid performing any other work on the machine while the game is being played, including background system tasks such as one that periodically indexes the contents of the file system.
The synthetic “virtual environment” application used in this experiment requires 10 ms of CPU time to render a single frame. The average frame rate must not fall below 30 FPS and furthermore, there must not be a gap of more than 33 ms between any two frames. If such a gap occurs, the test application registers the event as a deadline miss. The practical reason for this requirement is that in addition to degrading the visual experience, lag in virtual environments and games can lead to discomfort and motion sickness. Frame rates higher than 30 FPS are acceptable and desirable. Since each frame takes 10 ms to render, the hardware can render at most 100 FPS.
Table 10.5 shows the results of running the real-time application and background threads concurrently using different schedulers. Each line in the table describes the outcome of a single 30-second run. The percentage of the CPU received by the real-time application is %a and the average number of frames per second produced by the real-time application is FPS (which is equal to the percentage because it takes 10 ms, or 1% of 1 s, to produce each frame). The number of times the real-time application failed to produce a frame on time during the experiment is listed under “misses” and finally, the total percentage of the CPU received by background threads, if any, is %b.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
The middle cluster of lines in Table 10.5 shows the effects of running the real-time application alongside a single CPU-bound background thread. In this experiment, background threads were always run at the default time-sharing priority. The scheduling behavior of the real-time application when given a hard CPU reservation is the same as in the case of no contention: it achieves slightly more than the minimum required frame rate, and misses no deadlines. Given a soft CPU reservation, the real-time application and the background thread share unreserved CPU time--this is the desired behavior. Without a CPU reservation, the real-time application is unable to gracefully share the machine with the background thread. When the real-time application is scheduled at a higher priority than the background thread, the background thread is not able to make much progress: it runs only occasionally, when its priority is boosted by the heuristic that we mentioned in Section 9.2.2 , that prevents threads from being completely starved regardless of their priority. Notice that although the background thread only received about 3% of the CPU time during this test, it still caused the real-time application to miss six deadlines. When the real-time application is run at the same priority as the background thread it is unable to meet its deadlines even though it is receiving more than enough processor time: the time-sharing scheduler time-slices between the two threads at a granularity too coarse to meet the scheduling needs of the real-time application. When the real-time application is run at a priority lower than that of the background thread, it is scheduled only occasionally and provides few frames.
The situation where there are ten background threads is similar to the situation where there is one: the real-time thread only meets all deadlines when given a CPU reservation.
In conclusion, only a soft CPU reservation provides the desired scheduling behavior in this example: a hard CPU reservation precludes opportunistic use of spare CPU time to provide a high frame rate, and no CPU reservation precludes sharing the machine with background threads.
HLS was designed to use low-cost, constant-time operations when making scheduling decisions. Beyond this design, little effort was put into optimizing the HSI or the loadable schedulers. They could be optimized by:
In principle, there does not appear to be any reason that context switches involving a single hierarchical scheduler should be any more expensive than context switches in the released Windows 2000 scheduler. Scheduling decisions involving many loadable schedulers will unavoidably add some overhead.
This dissertation supports the thesis that HLS is feasible and useful, and this chapter contained material supporting both points. Data showing that HLS mode-change operations are cheap and that HLS causes a modest increase in context switch time support the feasibility argument, and quantitative data about application performance when scheduled by loadable schedulers supports the argument for the usefulness of HLS.