Racket-on-Chez Status: January 2018 [extended version]
Unless youre especially interested in implementation details, see the shorter version of the report on the Racket blog. Additions here are marked with “[extended].”
It’s been almost a year since we decided to try running Racket on Chez Scheme, and it has been almost six months since my last status report. As of RacketCon 2017, DrRacket could start up on Chez Scheme (but just barely, and just in time for the demo).
The current implementation is now considerably more complete. DrRacket still doesn’t run well, but Racket-on-Chez can build a full Racket distribution in reasonable time and space.
With the current Racket-on-Chez compilation strategy, runtime performance is plausible on traditional benchmarks, but cross-module optimization is needed to bring the results fully in line with our expectations. Startup and load times are much slower than we would like. Compile/build times are a factor of 4 slower than the current version of Racket.
Glossary of implementations:
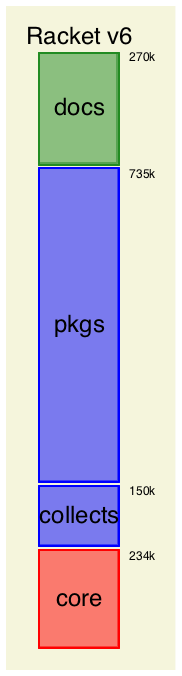
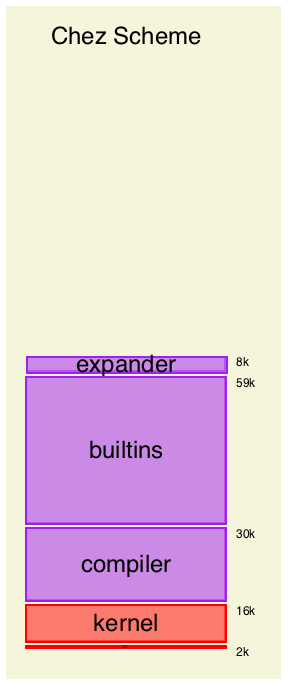
Racket —
the current Racket release, version 6.x racket7 —
mostly the same as Racket, but using a new, Racket-implemented macro expander; the source is in the https://github.com/racket/racket7 repo Chez Scheme —
a completely different implementation of Scheme that we’re trying to use as a replacement for part of Racket Racket-on-Chez —
Chez Scheme plus additional layers to make it implement the same language as Racket; the source is also in the https://github.com/racket/racket7 repo
Approach
Our overall goal is to improve Racket’s implementation and make it more portable to different runtime systems. To a first approximation, improving Racket and making it more portable means “less C code.” Building on a Chez Scheme is a promising means toward that end.
|
|
|
|
|
|

|
|
|

|
|
|
|
|
|
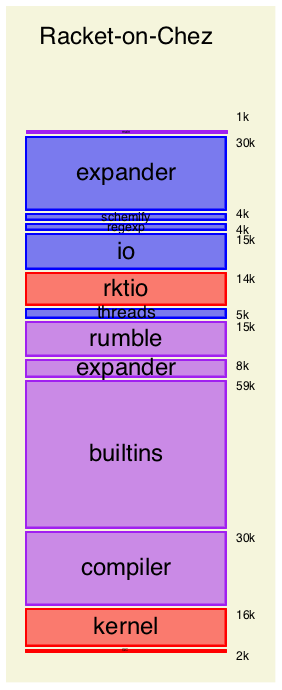
The expander block (the same as for racket7) sits on a small schemify adaptor. The schemify layer converts Racket linklets into plain Scheme functions, adjusting expressions as needed to support applicable structures, to enforce left-to-right evaluation, and to implement Racket’s allocation model for local functions (i.e., lift to avoid closure allocation whenever possible).
Naturally, the Racket-on-Chez implementation is bootstrapped by applying the expander and schemify layers to themselves and the other Racket-implemented parts of the stack, and then compiling the schemified linklets using the Chez Scheme compiler. A thin main driver on top handles command-line arguments to load modules and start the read–eval–print loop.
Current Functionality
DrRacket starts up in Chez Scheme, and just starting DrRacket exercises many Racket language constructs and libraries. The largest Racket-on-Chez demonstration to date is building all of the packages and documentation of the main Racket distribution. Building packages and documentation, again, covers more Racket functionality than you may expect, because our macros do interesting things, such as typechecking and generating bitmap images. Also, the build process is too long and complex to tolerate leaks or major inefficiencies.
Still, many pieces are buggy, and closing the gap is mostly a matter of plowing through the Racket test suites.
A few large pieces are still missing:[extended]
There’s no racket program that starts Racket-on-Chez, there’s no DrRacket executable to start DrRacket on Chez Scheme, and so on.
For now, Racket-on-Chez runs via make run ARGS="..." in the Racket-on-Chez build directory. In the near future, there will be a way to generate racketcs, DrRacketCS, etc., alongside racket. In the more distant future, if things work out, racketcs will become racket by default.
Futures are not fully supported.
Sarah continues to work on futures.
Places are not supported.
Adding places still seems straightforward, but I haven’t tried.
Windows is not yet supported.
... almost certainly, although I haven’t tried it.
Unicode support at the level of character classifications and string conversions needs to be sorted out.
I don’t know how well Racket and Chez Scheme line up already, so this may be easy or difficult.
Primitive error messages are not good.
There’s a basic bridge in place to convert Chez scheme errors into Racket errors, but more work is needed to make error messages consistent and detailed.
Custodian-based memory accounting is not yet supported.
Support for memory accounting looks tractable in the long run.
Incremental garbage collection is not supported.
Incremental GC remains a low priority. Chez Scheme’s garbage collector may or may not work well enough as-is for the programs that motivated incremental GC in Racket.
Single-precision and extended-precision floating-point numbers are not supported.
These remain a low priority, and supporting them appears to require significant changes to Chez Scheme.
Besides unsupported functionality, there are currently a few incompatibilities with Racket. Most incompatibilities are in the foreign-function interface. The following is an incomplete list, but it illustrates the kinds of differences that remain.
The eq? operation is not defined on flonums, and (eq? x x) does not hold in general.
I’m not sure, but we may just have to compromise compatibility and definedness on this point. It’s worth noting that an eq?-based hash table does not work for associating values to floating-point numbers, and I’ve changed one or two libraries to use eqv?-based hash tables.
The letrec form does not always behave as Racket’s model specifies when the right-hand side returns multiple times (through a captured continuation).
I haven’t thought enough about this one, but I worry that it will be difficult to change.
A foreign pointer cannot be turned into a Racket byte string using make-sized-byte-string.
Chez Scheme’s representation of byte strings doesn’t point to a separately allocated byte array in the way that Racket’s representation does. This incompatibility has affected several libraries, but so far, I was able to adapt them easily to use an approach that works in both Racket implementations.
The 'atomic-interior allocation mode for malloc returns memory that is allowed to move after the cpointer returned by allocation becomes unreachable.
Ditto.
Memory allocated with malloc’s 'nonatomic mode works only in limited ways.
Memory allocated as 'nonatomic is not actually an array of pointers, so it cannot be usefully passed to foreign functions. I have not yet encountered libraries where this is a problem.
Performance: Benchmark Sanity Check
The overall compilation story is not yet right in Racket-on-Chez, partly because there’s no cross-module optimization. Functions like map, memq, and assv need cross-module optimization to be compiled well in Racket-on-Chez. Benchmarks sometimes do not rely on cross-module optimization, however, and preliminary benchmark measurements can be useful as a sanity check on the ways that schemify mangles individual modules.
Benchmarks are in the racket-benchmark package whose source is in the racket7 repo. The benchmarks run in Chez Scheme as R6RS libraries. The difference between Racket and racket7 is in the noise.
The table below shows a handful of rough benchmark results. You should not take the results seriously, but they line up with my overall impression of where we are.
|
| Rough and unscientific benchmark numbers |
|
| ||||||||||||||||||||
|
| msecs |
| deriv |
| dynamic |
| sboyer |
| maze |
| nfa |
|
| ||||||||||
|
| Chez Scheme |
| 770 |
|
|
| 360 |
|
|
| 1270 |
|
|
| 930 |
|
|
| 2100 |
|
|
|
|
|
| Racket-on-Chez |
| 1560 |
|
|
| 1030 |
|
|
| 1470 |
|
|
| 1520 |
|
|
| 2200 |
|
|
|
|
|
| Racket |
| 2030 |
|
|
| 560 |
|
|
| 2230 |
|
|
| 1330 |
|
|
| 4100 |
|
|
|
|
All benchmarks were run in safe mode and without Gustavo’s work-in-progress addition to the Chez Scheme compiler that can eliminate some runtime checks and related dead code.
Performance: Startup
Startup time for Racket-on-Chez is determined by Chez Scheme’s base startup time (to load boot files) plus time to load the expander and other parts of the Racket-on-Chez stack. The load times shown below for racket/base and racket include the startup time and add the additional time needed to load the many compiled files that are parts of those libraries.
For Racket and racket7, bytecode parsing can be delayed at the granularity of a procedure, so that a procedure’s bytecode isn’t parsed until the procedure is called. Delayed parsing is enabled by default, and the -d flag disables it.
Startup/load time
msecs
startup
-l racket/base
-l racket
Racket
16
50
220
Racket -d
16
80
500
racket7
50
110
340
racket7 -d
50
190
650
Chez Scheme
170
Racket-on-Chez
440
550
1200
Racket-on-Chez/JIT
440
550
1600
Compared to the current Racket version, starting up and loading takes longer in racket7, because racket7 has to load embedded bytecode for the expander’s implementation, and because the bytecode encoding of linklets has not been refined as much.
The Chez Scheme row in the table doesn’t actually load
racket/base, but that’s the closest reasonable column.
That row corresponds to just starting Chez Scheme with its
compiler—
Loading Racket-on-Chez takes significantly longer, still, due to larger and slower-to-load machine code for both the Racket-on-Chez stack and libraries compiled with it. Although individual linklets within a module (roughly, individual phases) are parsed on demand, there is no delayed parsing at the granularity of procedures, so the work performed by loading is closer to the Racket -d and racket7 -d rows.
The last row above, Racket-on-Chez/JIT, refers to a variant of Racket-on-Chez that does not compile whole linklets. Instead, it keeps individual lambdas in source form until called, and it compiles each called lambda on demand. Load times go up, mostly because code is compiled as needed, but also because the source-fragment representation is even larger than machine code right now. The Racket-on-Chez/JIT approach does not look the most promising, so far, but it’s also not crazy. With more effort and tuning (especially in the representation of source fragments), it may be a viable approach and more in line with the way the current Racket implementation works.
Clearly, load time is a direction for further effort.
Performance: Expander and Compiler
The expander runs at about the same speed in Racket-on-Chez and racket7, but the linklet-compilation step takes much longer in Racket-on-Chez. As a result, compilation time for Racket-on-Chez dominates expansion proper for a task like racket -cl racket/base.
Reported times in this section use a Racket-on-Chez stack that is compiled in unsafe mode and run on a 2013 MacBook Pro 2.6GHz Core i5. Unsafe mode improves expand and read performance by about 10%.
Steps within racket -cl racket/base
msecs
expand
schemify
compile
eval
read
racket7
2511
662
235
275
Racket-on-Chez
2398
917
2852
390
227
Racket-on-Chez/JIT
2441
974
1044
515
229
For Racket-on-Chez/JIT, compile times go down, showing that about 1/3 of the code that is compiled during expansion is also run during expansion. The fraction would be lower for most programs; the racket/base library is unusual in building up layers of macros to implement itself. The schemify step is certainly a target for improvement, since its job is much simpler than the compile step’s job.
[extended]Racket-on-Chez compile times are longer than racket7 compile times because the Chez Scheme compiler does more. About half of the Racket compiler’s work corresponds to Chez Scheme’s cp0 pass, and Racket’s compiler/JIT lacks a general-purpose register allocator. Here’s a table of cumulative times spent in Chez Scheme compiler passes while loading racket/base from source (summing roughly to the 2852 millisecond total in the previous table, although there’s noise so that the numbers won’t match exactly):
Chez Scheme compiler passes during racket -cl racket/base
msecs
cpletrec
35
np-expand-primitives
37
np-place-overflow-and-trap
40
np-optimize-pred-in-value
46
np-expose-allocation-pointer
48
np-impose-calling-conventions
51
expose-overflow-check-blocks!
56
np-expand-hand-coded
60
do-live-analysis! *
87
assign-new-frame! *
87
np-expose-basic-blocks
101
assign-registers! *
105
do-unspillable-conflict! *
116
finalize-frame-locations! *
116
do-spillable-conflict! *
128
finalize-register-locations! *
130
expand
149
cp0
200
select-instructions!
304
np-generate-code
351
other short passes total
504
The steps marked with * are primarily about register allocation, and those total to 770 milliseconds.
That factor-of-2 slowdown relative to racket7 is compounded by the Racket-implemented expander being twice as slow as the current Racket’s C-implemented expander:
Loading from source with racket -cl
msecs
racket/base
racket
Racket
1830
21700
racket7
3490
38140
Racket-on-Chez
7060
70093
Racket-on-Chez/JIT
5400
55050
The gap between the Racket-implemented expander and the C-implemented expander is the one that we most hoped to close by moving to Chez Scheme. As part of the Racket-on-Chez stack, the expander is already compiled in a reasonable way (i.e., no cross-module optimization issues), so it’s not clear how to improve. Still, I still think the expander can be made to run faster in Chez Scheme, and we’ll keep trying.
Performance: Distribution Build
The current version of Racket-on-Chez builds on a 64-bit machine with a peak memory use around 1.25 GB, which is on a similar scale to the current Racket release’s peak memory use around 1 GB.
The following plots show, on the same scale, memory use over time when building a distribution. Each plot has two black lines (easiest to distinguish in the last plot): the top black line describes peak memory use, since it’s before a major GC, while the bottom black line is closer to live-memory use, since it’s after a major GC. The orange region is for compiling libraries (each vertical line starts a collection), the blue region is for running documentation, the green region is for rendering documentation, and the final pink region is for re-rendering documentation as needed to reach a fix-point for cross references. Memory use is expected to grow modestly during the blue region, since the builds collecting cross-reference information for use in the green region. Memory use should grow minimally in the orange and green regions (as a side-effect of caches).
These graphs report builds on a Linux 3.4GHz Core i7-2600 machine with the Racket parts of the Racket-on-Chez stack compiled in safe mode.
Racket
C-implemented expander
racket7
Racket-implemented expander
Racket-on-Chez
Same expander as racket7



The plots illustrate that, while memory use is similar, build times are much longer. Expander and compiler performance largely explains the difference.
The build time certainly can be improved some. Maybe build times can be improved significantly, or maybe slower build times will seem worthwhile for a more maintainable implementation of Racket and/or for faster generated code.
Changes to Chez Scheme
[extended]
There are many good virtual machines in the world, but none starts
remotely as close to Racket as Chez Scheme—
Currently, running Racket-on-Chez requires the fork at http://github.com/mflatt/ChezScheme. With one exception that will be remedied eventually, all of the changes in the fork have been submitted as pull requests at http://github.com/cisco/ChezScheme. Nine or so pull requests have been merged, and eight or so are currently open. In addition, Kent and Andy invested significant effort to improve the register allocator to help support Racket.
For the record, here is a summary of the main changes:
Add immutable strings, byte strings, vectors, and boxes. [merged]
Adding wrappers to enforce immutability would be expensive, so built-in immutable variants help considerably.
Racket’s pairs differ from vectors, etc., in that mutable and immutable pairs are distinct types. Immutable pairs are Chez Scheme’s pairs, made effectively immutable by just not exposing set-car! and set-cdr! at the Racket level.
Configurable equality and hashing for records. [merged]
Chez Scheme’s built-in equal? and equal-hash functions now support configuration for record types. Although Racket-on-Chez ended up reimplementing equal? and hashing to support impersonators and chaperones, the reimplementation uses the same hooks.
Record line and column information in source objects. [merged]
Chez Scheme’s technique of on-demand line and column counting did not fit well with Racket’s view of source locations.
Add ephemerons. [merged]
Many parts of Racket rely on ephemerons to avoid key-in-value leaks.
Ordered finalization via guardians.
Internally, the current Racket implementation has three levels of finalization, which allows system finalization to happen later than client-visible finalization. Ordered guardians achieve the same result in a more composable way.
Support struct and union arguments and return values for foreign functions.
C struct arguments and return values are a pain, but they’re necessary for various Racket foreign-function bindings, including the drawing and GUI libraries.
Add compiler optimizations based on type reconstruction.
Gustavo’s work-in-progress addition to the Chez Scheme compiler introduces the kinds of optimizations that he has long built and maintained in the current Racket implementation. For example, (f (car x) (cdr x)) can be optimized to (f (car x) (unsafe-cdr x)). These optimizations are particularly helpful for structure-field access and update, and preliminary measurements suggest that the optimizations can provide about half of the performance benefit of unsafe mode (so, typically 5-10%) without the unsafety.
Add backreference reporting to the garbage collector.
This change is the one that doesn’t have a pull request, yet. It extends the garbage collector to report, for each live object, a referencing object that kept it alive. This tool has been essential to tracking down memory leaks, but Chez Scheme’s inspector provides features that might be extended instead of adjusting the garbage collector.
The current Racket implementation provides this information only if you build in a special way and use a poorly documented interface, and it’s somewhat unreliable. Chez Scheme’s nicer garbage-collector implementation made the feature easy to add and to have always available.
Make the register allocator more scalable. [partly merged]
Chez Scheme’s compiler uses a graph-coloring register allocator that is by default quadratic in time and space. Changes by the Chez Scheme authors avoid quadratic behavior in most cases. A pending pull request covers additional cases that show up in practice for Racket.
The more general repair for Racket-on-Chez has been to avoid sending overly large expressions to the Chez Scheme compiler. For example, the pending pull requests provides linear-time behavior for a real Racket module, but the constant factor is still too large. Large code fragments tend to correspond to top level of a Racket module, and a custom interpreter works well for those cases.
Outlook and Plans
It would be nice if porting to Chez Scheme made every aspect of Racket magically faster. It hasn’t done that, but we have plenty of room for improvement; the performance results to date are a lower bound on performance, not an upper bound.
Keep in mind that the original goal is not to have a faster Racket, but a better-implemented Racket with acceptable performance. The Racket-on-Chez implementation is far more maintainable and flexible than the current Racket implementation, so maybe we’re half-way there after one year of work.
Some immediate next steps are clear: [extended]
Implement cross-module optimization.
Currently, I expect to implement cross-module optimization by adding inlining, constant folding, and constant propagation, and copy propagation to the schemify layer. Although that approach duplicates work that Chez Scheme’s compiler can do already (if cross-module information were somehow communicated to the compiler), it’s a relatively straightforward source-to-source transformation that fits naturally into work that the schemify layer performs already (I think). Also, putting high-level optimizations at the schemify layer will make them available to future Racket ports.
Generate racket, etc., executables that run Racket-on-Chez.
This task is mostly a matter of creating build scripts. In the end, building should be as easy as make cs in the top level of the Racket repo.
Implement places.
Obviously.
Make all of the Racket test suites pass (except for single-precision floating point, extended-precision floating point, and memory accounting).
It might seem that passing tests would be step 0 instead of step 4, but test suites turn out to be inconvenient to use on a slow and broken implementation, so I’ve interleaved test-suite work with everything else.
That’s a couple of months’ more work, at least.
Suppose that the result has good runtime performance compared to the current Racket implementation, but it’s still slower to compile and load by about a factor of 4. (I think that’s a fairly likely result, given the current trajectory.) Then what? I’m not sure, but I’ll keep trying and give it the rest of the second year.
You can try Racket-on-Chez from https://github.com/racket/racket7/. See racket/src/cs/README.txt in that repo for more information.